
前言
最近将部分工作流从 OpenClaw 切换到 Hermes 上进行了,也试用了一个多周。只能说各有千秋,不过总体感觉下来 Hermes 更适合当我的个人助理。
- Hermes 的处理速度和消息回复速度感觉明显比 OpenClaw 快很多
- 虽然 Hermes 没有多显式的多 Agent 架构,但是我的工作流也很适配 Hermes 的处理逻辑。我只需要将原本 OpenClaw 的 Agent 配置转成适配Hermes 的 Skill,也能很好地实现我的需求。
- Hermes 的自我进化我觉得大部分情况下是好用的,但也有不好用的时候。从我的体感上来说,Hermes 自我进化就是可以自动将一些约定存到记忆系统,能自动将与用户达成的共识生成Skill。但就是这个自动生成,反倒有时候不太好用。
在好几天的折腾之后,目前形成了一套相对稳定的工作流,值得记录一下。
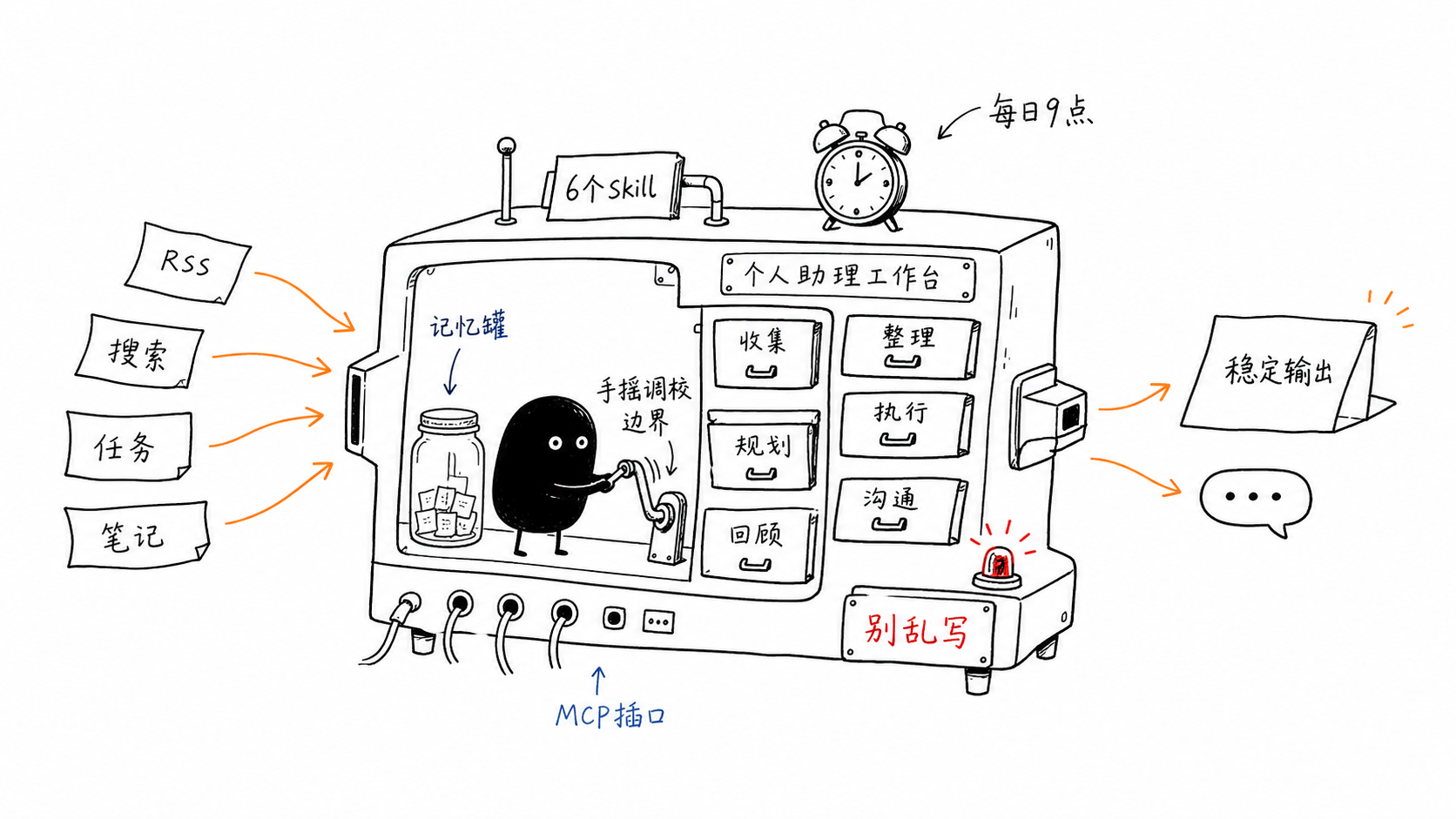
系统架构总览
用户对话入口 │ ├─ 📦 核心 Skill 层(6 个自定义 Skill) │ ├─ 📝 siji-flomo → Flomo 笔记系统 │ ├─ 📰 siqing-digest → 定时 RSS 摘要 │ ├─ 🔍 siqing-search → 实时情报搜索 │ ├─ ✅ siwu-ticktick → 任务/待办管理 │ ├─ 🚰 knowledge-pipeline → 知识处理流水线 │ └─ 💭 workflow-design → 工作流设计/讨论 │ ├─ 🔌 MCP 工具层(6 个服务器) │ ├─ Flomo MCP → 笔记读写 API │ ├─ TickTick MCP → 任务读写 API │ ├─ Miniflux MCP → RSS 订阅 API │ ├─ Jina MCP → 网页内容提取 │ ├─ GitHub MCP → GitHub 操作 │ └─ Notion MCP → Notion 操作 │ ├─ ⏰ Cron 定时任务层(1 个活跃任务) │ └─ daily-rss-digest → 每日 9:00 RSS 摘要推送 │ ├─ 🧠 Memory 持久记忆层 │ ├─ OpenViking 记忆引擎 │ ├─ 用户 Profile(偏好、时区) │ └─ 系统规则与边界约定 │ └─ 📡 消息推送层 ├─ Telegram 渠道 ├─ 飞书渠道(主要) └─ 终端渠道📦 六大核心 Skill
📝 siji-flomo - Flomo 笔记系统
这是我用到比较多 Skill,主要用于约束 Flomo MCP 的调用,以及标签规划和一些注意事项
触发词:记一下、存到 Flomo、整理笔记、标签整理、知识卡片
职责边界:
- 负责所有 Flomo 笔记的创建、查询、标签管理
- 严格的标签层级规范:#Area/ #Project/ #Resource/ #Inbox #Idea #Todo #Star
- 强制工作流:写入前必须先加载本 Skill → 获取格式规范 → 获取标签规范 → 确认现有标签
核心规则:
- 所有新笔记默认带 #Inbox 标签
- 默认复用现有标签,不随意创建新标签
- AI 只负责记录客观事实,绝不写用户的主观感受
📰 siqing-digest - 定时 RSS 摘要
用于约束我使用 Miniflux MCP 的规则,以及总结新闻时的规则和输出格式
触发方式:Cron 定时任务自动调用
职责边界:
- 唯一信息来源 = Miniflux MCP
- 绝对不使用 Web Search
- 极简摘要输出,无交互
核心功能:
- 自动识别「聚合新闻」vs「单条新闻」
- 聚合新闻拆分子条目,按用户兴趣筛选 Top 5
- 推送后自动标记 Miniflux 条目为已读
- 用户兴趣画像:前端技术、AI 开发工具、独立开发、知识管理
🔍 siqing-search - 实时情报搜索
用于获取实时新闻的规则,以及最重要的三级智能反馈机制,帮我深入了解一些新闻
触发词:最近动态、查一下外部信息、社区怎么说、这消息靠谱吗
职责边界:
- 纯 Web Search + Jina 读取
- 绝对不使用 Miniflux
- 完整的三级来源验证机制(P1 官方 → P2 可信 → P3 社区信号)
核心功能:
- 三级智能反馈:兴趣匹配 → 深入挖掘 → 持续监控
- 链接有效性强制验证(curl -I 校验 200 状态码)
- 信息分类标签:Fact / Vendor Claim / Expert Interpretation / Opinion / Rumor
✅ siwu-ticktick - 任务/待办管理
也是主要用于约束调用滴答清单 MCP,但不常用,只是偶尔用于复盘之前完成的 TODO
触发词:提醒我、加到滴答清单、创建待办、今天要做什么、排优先级
职责边界:
- TickTick 是执行系统,不是想法存储库
- 严格的授权机制:用户明确说「创建」才写入
- 时间硬边界:模糊时间不强行写入,先询问确认
核心类型:
- Task:有明确下一步动作的任务
- Reminder:有明确触发时间的提醒
- Schedule:会议、预约等日程类项目
- Progress Tracking:进度查询与复盘
🚰 knowledge-pipeline - 回顾工作流
用于回顾和整理 Flomo 上的笔记工作流,从聊天中产生新的想法和笔记
触发词:整理 Inbox、周报素材、月报素材、准备博客、资源整理
5 阶段完整流水线:
| 阶段 | 触发场景 | 核心动作 |
|---|---|---|
| Stage 1 | #Inbox 清理 | 分类打标签 → 用户确认后修改 |
| Stage 2 | 周回顾 | 本周 #Star 笔记 → 协作讨论 → 周报草稿 |
| Stage 3 | 月回顾 | 跨周模式识别 → 构建「思想小系统」 → 月度大纲 |
| Stage 4 | 资源整理 | 摄影/读书等专项资源沉淀 |
| Stage 5 | 博客发布 | 成熟主题 → 素材补充 → 结构协作 → 用户手动写作 |
核心原则:
- AI 只有「检索」和「整理材料」能力
- AI 绝不直接写完整报告,所有主观内容用户自己写
- 绝不自动同步,手动复制本身就是思考过程的一部分
- Flomo = 快速捕获,Notion = 结构化沉淀(人工迁移)
💭 workflow-design - 工作流设计与讨论
参考 superpowers 的 brainstorming(头脑风暴)设计的 Skill,用于详细讨论某个话题
触发条件:仅当用户明确说「我们来讨论一下…」「帮我设计…」时才激活
3 阶段工作流:
- 访谈与探索模式 → 一次只问一个问题,边讨论边提出 2-3 个方案 + 权衡,不等到最后才给方案
- 总结可执行计划 → 列出所有共识、下一步、边界约束
- 明确授权后执行 → 用户说「开始」才真的动手改
内置模式库:
- 5 种结构化讨论模式(视角乘法、约束变异、反向思考、类比迁移、假设挑战)
- 防坑清单:避免无结构的「头脑风暴」、避免一次性问太多问题
超级安全锁:讨论 Skill 本身的设计时,绝对不能在讨论过程中修改这个 Skill 的任何文件,必须等用户明确说「可以改了」才行
超级安全锁 就是专门针对 Hermes 自我进化加入的规则。当我和他讨论 SKill 本身时,虽然看起来他还在问问题让你确认当前设计是否合理,实际上他已经更新到对应的 Skill 文件了。
所以对话时经常出现:「好的我现在来更新Skill。我注意到本次共识已经被更新了,我来检查一下是否一致。。。」
🔄 Skill 之间的配合
用户说「这个消息靠谱吗?」 ↓ 触发siqing-search 🔍 ↓ 搜索验证 + 三级反馈 ↓ 用户选择「需要跟进」 ↓ 移交siwu-ticktick ✅ → 是否创建跟进任务 ↓ 或siji-flomo 📝 → 是否记录为知识笔记 ↓ 是knowledge-pipeline 🚰 → 进入知识处理流水线定时 9:00 触发 ↓siqing-digest 📰 ↓ Miniflux 获取内容 ↓ 生成摘要飞书 / Telegram 推送 📡 ↓ 用户看到后感兴趣 ↓ 触发后续操作siqing-search 🔍 → 深挖siwu-ticktick ✅ → 跟进任务siji-flomo 📝 → 笔记沉淀🔌 MCP 服务器配置
| MCP 服务器 | 连接方式 | 主要工具 |
|---|---|---|
| Flomo | HTTP Stream | memo_create / memo_search / tag_tree / memory_context |
| Dida365 | HTTP | 任务 CRUD / 项目管理 / 提醒设置 |
| Miniflux | Docker Stdio | get_daily_digest / get_entries / update_entries_status |
| Jina | HTTP Stream | web_search / read_url / extract_pdf / screenshot |
Miniflux MCP
Miniflux MCP 原项目是我在 Github 上找的,但是他已经半年多没更新了。我怀疑有些新的 API 未适配或者需要修改,我就将它 Fork 后自己用 Codex 重新检查并重构了一遍,加入了日报的功能接口,方便 Hermes 在推送RSS日报时能更省 Token 一点。
如果你也有类似需求,可以试试:https://github.com/LetTTGACO/miniflux-mcp
Jina MCP
由于 Hermes 没有像 OpenClaw 那样内置基于免费的 DuckDuckGo 的 Web Search,而 Jina 是去年我做其他项目时用到的工具,他的搜索功能很强,而且免费(不过我去年充值过,额度非常非常多)。于是我就用它替代了大部分的网页解析过程。
⏰ Cron 定时任务配置
已激活:daily-rss-digest
- Schedule:每天 9:00(0 9 * * *)
- 推送目标:飞书 Home 频道
- 加载 Skill:siqing-digest
- 启用工具集:MCP + Terminal + Execute Code
- 执行流程:获取 Flomo 兴趣画像 → Miniflux 24h 未读 → 生成摘要 → 标记已读
🧠 Memory 持久记忆系统
记忆引擎:OpenViking
我买了火山引擎的 Coding Plan,他有送 OpenViking 的额度,所以我就配置上去了。因为他主要优化长期记忆,目前来看没有明显的提升,再使用一段时间之后再来看吧。
- 用户 Profile 记录:沟通偏好、时区、兴趣领域、输出格式规范
- 系统规则记录:Skill 边界约定、修改锁规则、渠道适配规则
- 重要原则:讨论中的临时共识绝不自动写入记忆,只记录共识,99% 的内容只留在对话历史中
Hermes Auxiliary 配置优化
我的主模型是 MiniMax M2.7(纯文本,不支持视觉)。直接发图片过去会导致Hermes 走内置的 vision_analyze 工具来分析图片,而这个工具经常报错。看了下官方文档,可以给一些功能单独设置模型。
在配置文件中给 auxiliary 槽位配置支持视觉的模型,让不同任务走不同模型,兼顾能力 + 成本,顺便也优化了其他工具的模型调用
豆包的
doubao-seed-2.0-lite最近刚更新了一版,其能力已经和自家的 Pro 不相上下了,但是比Pro 更省 Token 一些, 所以很多场景就尝试用 lite 模型去处理了,我准备观察一段时间再调整。
| 配置项 | 主要用途 | 典型触发场景 | 对质量影响 | 适合模型 |
|---|---|---|---|---|
| approval | 审批/确认类判断 | 判断某个动作是否需要用户确认、是否允许继续执行 | 中低 | doubao-seed-2.0-lite 足够 |
| compression | 上下文压缩、摘要、历史裁剪 | 对话变长时压缩上下文,避免主模型上下文爆掉 | 高 | 主模型 |
| curator | 信息筛选、整理、判断重点 | 新闻筛选、网页结果整理、从大量内容中挑重点 | 高 | 主模型 |
| mcp | MCP 工具调用辅助 | flomo、滴答、GitHub、RSS 等 MCP 工具调用前后的参数理解 | 高 | 主模型 |
| session_search | 当前会话/历史会话搜索 | 找“刚才说过的配置”“前面提到的模型”等上下文 | 中 | doubao-seed-2.0-lite 足够 |
| skills_hub | Skill 选择/路由 | 判断该用哪个 skill,比如新闻搜索、网页提取、MCP 操作 | 中高 | 主模型 |
| title_generation | 生成对话标题 | 自动给会话起标题 | 低 | doubao-seed-2.0-lite 足够 |
| vision | 图片理解 | 看截图、报错图、配置图、网页截图 | 高 | doubao-seed-2.0-pro 多模态模型 |
| web_extract | 网页正文提取/网页总结 | 抓网页、RSS、新闻、长文章内容 | 高 | 主模型 |
优化飞书渠道消息展示
Hermes 原有飞书渠道的消息发送逻辑:发送普通消息并通过 im.v1.message.update 反复编辑来流式传输网关响应。这种路径可行,但我个人觉得还挺别扭的:
- 飞书客户端会显示【已编辑】的行为,且编辑率行为与飞舒原生的 AI 卡流式模型不同。
- Markdown 文本支持不全,表格和其他一些样式几乎没有美感
所以我花了几天时间使用 Codex,一边帮我了解源码架构,一边寻找可行的解决办法。经历了3版技术文档,终于算是开发并冒烟测试完成了。已经提了个 PR 到官方仓库了:https://github.com/NousResearch/hermes-agent/pull/23488
在PR未被合并之前,如果也想试用的话,可以直接将我的分支代码合并到主分支,然后替换掉 Hermes 中的相关文件,重启Hermes 网关即可。